- Published on
Syncing Adobe Launch/Tags with Github - Part 3: Extracting file contents with the Github API
- Authors
- Name
- Perpetua Digital
- john@perpetua.digital


So where exactly are we at?
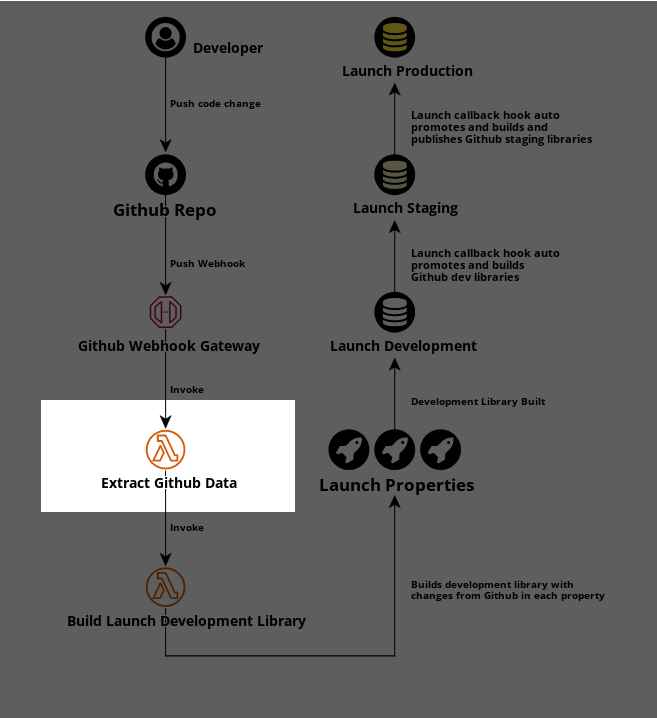
In this step, I am calling an AWS Lambda called Extract Github Data which will get the changed file contents from Github and prepare them to be sent to the Launch API.
The Push webhook is just a notification
In my previous post, I showed how to setup Github to notify me that a file update has occurred. When that happens, I check if I need to sync any changes from that update to components in Launch (just data elements for now). I also noted that the Github Push webhook doesn't give me the contents of a changed file, its just a notification. Now that I know a change occurred in a specific file, and that file is in my dataelements folder, I can go grab the contents of that file via the Github API.
Getting the most recent commit
In order to get thew newest file contents, I need to look at my repo's most recent commit for that file. From my webhook handler, I received all the information I need to look at the commit history using the Github API:
modified_data_element_filesan array the names of the data element files that changedownerthe owner of the repo - an individual or an organizationrepo- the name of of the repo
To see the commit history of a given file, I can make this call: https://api.github.com/repos/${owner}/${repo}/commits?path=${file}
Technically, I could skip this step because the push webhook does send me the most recent commit reference ID (ref) which is what I am looking for here in the commit history. However, I went the route of pulling the most recent ref ID its own call for a few reasons:
First, I needed to learn how to make authenticated calls to Github with a Github Personal Access Token (GPAT). A GPAT is how I will authenticate to the Github API to pull file contents. While my demo repo is public, in reality, someone using this process will likely be using a private repo so they will need to authenticate. Its also important to use a GPAT because API calls without one are subject to rate limiting.
Second, I didn't want to lock the whole flow into only being able to sync the most recent change. If, for example, I wanted to make some sort of rollback functionality, I would only need to refactor this call to do so.
The first item in the commit history response list will be my most recent commit, the second item will be my second most recent commit, and so on. Inside the most recent commit, will the ref I am looking for. Using this value, I can now make another call the Github API and ask for the most recent version of a specific file, contents and all. The ref value also comes in handy when naming things in Launch like libraries and environments.
You can see the commit history of a test file here:
https://api.github.com/repos/perpetua-digital/launch-property/commits?path=dataelements/test.js
Extracting the important stuff
The next call(s) will have the following URL structure. All authenticated by a GPAT. The number of calls will be dependent on how many files were changed. A call for each file in the modified_data_element_files array.
https://api.github.com/repos/${owner}/${repo}/contents/${file}?ref=${sha}
owner, repo, and file all came from my Webhook handler API gateway, and sha of course comes from the commit history call above. Assuming I pass this call the most recent ref value, this will give me everything I need I know about the newest version of this file and I can start extracting the important stuff.
The repo API will return my file contents encoded in Base64 so there is an extra step to decode them. Given this file:
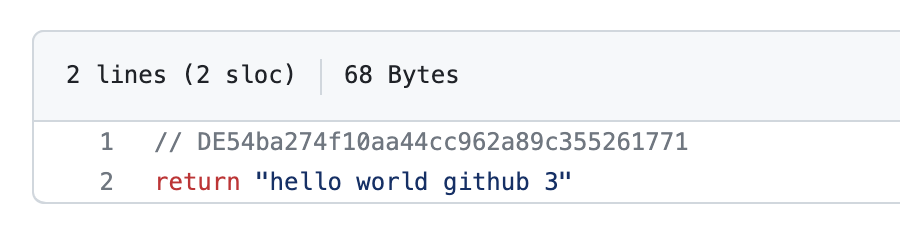
// api returns file contents encoded in base64
// 'Ly8gREU1NGJhMjc0ZjEwYWE0NGNjOTYyYTg5YzM1NTI2MTc3MQpyZXR1cm4g\nImhlbGxvIHdvcmxkIGdpdGh1YiAzIgo=\n'
// decode base64 to get file contents
const b64EncodedStringFromAPI =
'Ly8gREU1NGJhMjc0ZjEwYWE0NGNjOTYyYTg5YzM1NTI2MTc3MQpyZXR1cm4g\nImhlbGxvIHdvcmxkIGdpdGh1YiAzIgo=\n'
const sourceCode = atob(b64EncodedStringFromAPI)
console.log(sourceCode)
// '// DE54ba274f10aa44cc962a89c355261771\nreturn "hello world github 3"\n'
Remember how I was storing data element IDs in comments in Github files? Well, that is going to come in handy right about now.
I went the route of putting the IDs directly in the files because I couldn't think of any other way to relate Github files with data element IDs without having to build a database. Of course, if I used a database, then I need a front end to interact with it, then I need to host everything, etc. etc. You get what I'm saying. Though, should this project progress past the proof of concept stage, a front end is likely inevitable, but I digress...
Since Github returns me the entire contents, I need to extract the Data element ID(s) that this file should be synced with and save it/them.
Given the above Github file, this lambda's entire purpose is to build an array that looks like the following. This final array will contain all the changes that need to be sent to Launch.
data = [
{
file: 'dataelements/test.js',
fileContents: '// DE54ba274f10aa44cc962a89c355261771\nreturn "hello world github 3"\n',
dataElementIds: ['DE54ba274f10aa44cc962a89c355261771'],
sha: 'ABC1234....',
author_name: 'Perpetua Digital',
},
]
Next up
So now that I have a bunch of data element IDs and the contents that they need to be updated to, its time to talk to Launch. Once the above array is all built. I trigger the 3rd lambda which will build my changes into a development library. Finally, something interesting is happening!